
Boggle is easily one of my top 3 tabletop games. My family and I have burnt some serious midnight oil over the years trying to best each other at this addictive word game. It’s gotten competitive to the point where one of my uncles trained between family gatherings to avoid the previous shamings he had received by the rest of the family’s superior Boggle-ing abilities. It’s smart, strategic, fast-paced, unforgiving, and I love it.
I recently had the opportunity to learn about GPU-programming and all the wonderful parallel possibilities it promises, and decided that Boggle provided the perfect playground to test my new-found knowledge. So today I present my GPU based Boggle solver.
As always you can find the source code on my GitHub.
But Wait Miguel, What Is Boggle?

I don’t even know what to say…I’m just dissapointed dear reader. You’ve made me feel the opposite of how Shakespeare Bot 9000 made me feel. Well fear not, I’ll walk you through the basics.
Boggle is played on a 4×4 grid of letters, where the letters are randomly placed by shaking dice whose sides are each composed of a single letter (except for Q which is instead replaced by Qu). The purpose of the game is to find as many words as possible in 3 minutes, with all players searching for words simultaneously. Words can be formed by a sequential combination of adjacent letters, this includes diagonal, horizontal and vertical adjacencies, but no overlap is allowed. Each word must be at least 3 letters long and cannot reuse the same dice twice; for example, in the game below figure the word “SUPPER” could not be spelled because you would have to use the dice with the letter “P” twice.

Once the timer runs out, players compare words and any words which have been discovered by multiple players are crossed-off. The remaining words on a player’s list than contribute to his score based on the length of each word.
Ok, now that you understand how Boggle works you can buy it here, invite some friends over [Error: purchase link not found] and have the best night of your collective lives.
GPUs & GPU Programming
Graphic Processing Units (GPUs) are a special chips which can be found inside most modern personal computers (including yours) and are used to help create and manipulate computer graphics. They differ from Central Processing Units (CPUs) (the brain of your computer) because they are designed to process information in parallel, versus CPUs which are designed to process information serially. Whereas CPUs might have four very fast cores (such as the Intel Core i7), GPUs can have thousands of slower cores (2880 cores in the Nvidia Tesla K40). Although this design choice was originally to help with graphics, their potential for highly parallel computing have caused GPUs to be adopted by a huge range of fields; from machine learning to medical imaging. Or in painting as demonstrated beautifully by Mythbusters.
GPU Programming is simply programming in order to leverage the parallel capabilities of the GPU already in your computer!
Solving Boggle
Since finding enough words to beat your average human at Boggle isn’t a terribly difficult challenge, my focus with this project was to find all possible English words on the board efficiently – which is where the parallel processing power of GPUs comes into play. Clearly in this instance there is no purpose in implementing multiplayer competition as all algorithmic players will simply find all word on the board and thus all players will simply score 0. Since a 4×4 letter grid is somewhat restrictive, I made the program flexible enough to solve any NxN grid of randomly generated letters. Each board was searched for ~100,000 English words which came from this dictionary; the longest word contains 32 characters and is “dichlorodiphenyltrichloroethane”.
Algorithms
Below I outline 3 algorithms for solving Boggle board. The first is a CPU based proof-of-concept of the intended GPU algorithm, the second is a competitive CPU algorithm, and the third is the GPU algorithm.
Credit to Golam Kawsar’s blogpost for the non-parallel inspiration to the following algorithms.
CPU Algorithm 1: Naïve Word Search
This first algorithm was implemented as a proof-of-concept of the intended GPU algorithm. It also provided a naïve baseline upon which to compare performance gains from parallel computation. The algorithm is based on a naïve recursive search through every path in the letter grid for a given word. The algorithm simply involves taking a given word, searching for its starting letter on the grid, then if there is a match iteratively checking adjacent letters until the word is found (or not found). This is done in a recursive process such that at each at each recursive step the adjacent letters are checked to see if they match the current character in the word; recursion stops when the word is found or when no more letters can be checked without doubling back onto a letter which has already been used. Clearly this process is inefficient in the recursion process as it does repeated searches for starting substrings of multiple words; i.e. care and careful have matching starting substrings, but the whole word search is repeated for both.
CPU Algorithm 2: Prefix Word Search
The second CPU algorithm was implemented in order to provide a better comparison baseline for any performance gains made by the GPU algorithm. To the best of the my knowledge, this algorithm represents the fastest approach to serial searching for words within a letter grid.
To remove the waste of repeating computation for identical starting substrings, we can preprocess the dictionary as a trie. A trie, also known as a prefix tree, is a tree which stores a single character per node and where each node is the child of a sequence of letters which come before it in a word. The figure below shows a simple trie formed from 11 words. The white nodes are standard traversal nodes and the black nodes are “word end nodes” which means that a complete word is formed when these nodes are reached.

Storing our dictionary in this manner has several advantages. Firstly, it is more space efficient, as repeated prefixes are only stored a single time. Secondly, the approach is also much better suited to the game of Boggle, both intuitively and in reducing the search space.
The word search algorithm functions similarly as before, except that now each root letter on the board is assigned a specific prefix tree (which contain all the words which can be formed starting with that letter) and uses that prefix tree to spawn recursive processes on the adjacent letters which are present in the immediate child nodes of this tree. These adjacent letters are then assigned a portion of their parent’s prefix tree and so on and so forth. Each recursive path terminates when it reaches a leaf node and outputs a result when it reaches a “word end node”. This approach saves us the wasted computation of repeating starting substring searches. It also allows us to iterate only through the prefix tree generated for each starting letter tile, instead of across the whole dictionary.
GPU Algorithm
The implemented GPU algorithm leverages the fact that word searching can be parallelized across each word in the dictionary. For a single word this simply requires checking the NxN grid for any letters which match its starting letter, then traversing the adjacent letters until the whole word is found, or the word cannot be found.
More explicitly, given some word, the board is checked for the starting character in that word. If a letter tile matching the starting character is found, then this tile is added to the current word path and the word character index is incremented. This new tile then has its adjacent tiles checked for letter matches to the second character in the word. Every time a tile is checked it is marked as such, so that the failed worth path from the starting tile to that letter tile is not checked again in the future. Obviously, letter tiles in the current worth path are also not checked for matches to the current word character. If a character match is found, then the above process is repeated on the new matching tile. If a character match is not found, then we backtrack to the previous tile-character match and continue searching. The process ends when either the word is found or we have backtracked to the starting letter tile and all of its adjacent tiles have already been checked, thus we have failed to find the word. Since my GPU did not support recursion (also known as dynamic parallelism on GPUs), the kernel algorithm had to be written in a loop which maintained the state of the board and the current word path at every search step.
The above process was run in parallel with a different word for every thread in the hopes that by parallelizing across the dictionary, there would be significant speed ups when compare to the CPU algorithm. Depending on the number of threads run, and the size of the dictionary used, it may be possible for each thread to process only one or two words. As such I expected that the algorithm would be suitably parallelizable and be fast.
What I Thought Was Going To Happen
I thought there would be significant speedups with the GPU algorithm with respect to both CPU algorithms. In fact, since the GPU algorithm is unaffected by the size of the board (except for a slightly reduced search space along the edges), I expected that the running time of the GPU algorithm should be fairly constant for any board size. In comparison I expected that the running time of the naïve CPU algorithm would increase at least exponentially with the size of the board, and the prefix CPU algorithm would increase approximately linearly with the number of tiles on the board; this later scenario is because the number of prefix searches simply depends on the number of possible starting tiles.
Results
The algorithms were run on a GTX 860M with 1024 blocks and 5 threads per block (see next section for more information). For the results that follow, the Boggle grid was kept square while the side length was varied. This is because a square grid offers the highest complexity in search paths and thus represents the hardest scenario for the algorithms; this fact can easily be seen by considering the number of possible search paths in a square 5×5 grid versus a 1×25 grid. The result of the word searches were also compared to ensure that both the CPU and GPU algorithms found the same words on the board; in all cases this was true.
The plots below show the average running time of 20 iterations of the algorithms on various square Boggle boards. Each board was randomly populated with letters before being searched by each algorithm. The prefix tree building time and the time it took to transfer the dictionary from memory to the GPU were both ignored in the figures above as the focus was on algorithm running time and not on one-time overhead. As expected the Prefix CPU algorithm performs significantly better than the Naïve CPU algorithm, and the GPU algorithm without I/O (Input/Output) performs better than both. In addition, as was expected, the GPU algorithm without I/O has a near constant running time. The GPU algorithm with I/O, which includes transferring the Boggle board data from main memory to the GPU memory, has a similar trend to the non-I/O GPU algorithm, but with a constant time increase of ~0.4 seconds. As expected the bulk of the time used in our GPU algorithm is actually in data transfer. For small board sizes, this actually makes the GPU algorithm including I/O worse than the CPU Prefix algorithm; however, since the data transfer time is nearly constant it beats the CPU algorithms once the board’s side length reaches 5 tiles.

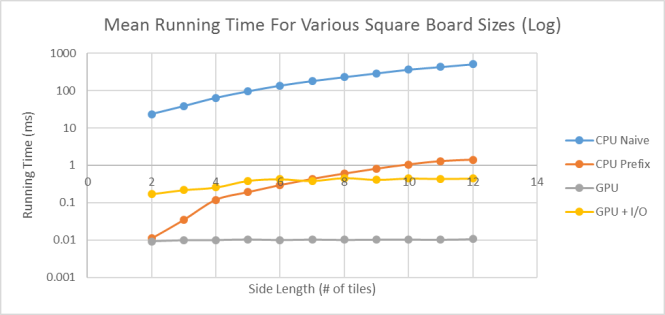
I should note that the first call to the GPU algorithm was always particularly slow with a running time of ~3.7 seconds. However, any subsequent call would run in ~0.01 (no I/O) or ~0.4 (with I/O) seconds as shown in the graphs above. The slow running time of the first call appears to be a peculiarity of my system and may be due to the time it takes for my laptop to switch from the on-board GPU to the external CUDA-compatible GPU (my laptop has 2 GPU’s). As such this value was considered an outlier and ignored in the graphs above since the focus was on the mean running time of the algorithm. In addition, this outlier actually contributes relatively little to the mean when performing many testing iterations.

The above table shows the time taken for overhead operations. Fortunately, each of these operations only has to be performed once, as they are constant given a dictionary; thus once constructed/loaded any number of Boggle boards can be solved without having to repeat this one-time overhead.

The figure above shows the number of words found for square boards with different square board sizes. Clearly as the board size increases, so does the average number of words found. However, since the number of words found depends highly on the random letters generated, there is high variance for all board sizes. The above graph is identical for all 3 algorithms since they find the same words for any grid.
Behind The Veil Of Perfection
Note: For a solid understanding of my analysis of the results one needs to know about blocks, threads, grids and warps in GPUs, so if you’re curious this Stackoverflow answer covers the first three pretty well, and this NYU course covers warps and thread divergence.

So the above results show the success of the approach and make using a GPU based algorithm for a Boggle solver seem very promising. But there are several unexpected limitations which I need to point out; and you may have already caught on to them if you were paying close attention.
You may have noticed that the largest board I tested was 12×12, and wondered why I limited myself to a relatively small board. Why not go bigger and really demonstrate the advantages of GPU programming? Unfortunately, the reason for this is that the size of the board is heavily limited by the available internal memory on a GPU.This is because every thread needs to maintain information regarding the word paths it has already visited so that it does not repeat the same search twice or get stuck in an infinite loop. Each thread also needs to maintain a list of its current word path and a copy of the word it is searching for. This puts heavy demands on the memory available to each thread, and since the required information to be stored scales with the size of the board (more tiles to be marked as previously travelled) the GPU can run out of memory for larger boards. As this memory is per block, this issue can be partially alleviated by decreasing the number of threads per block; hence why I used only 5 threads per block in the tests. On my laptop it was possible to solve a 12×12 board using 1024 block and 5 threads per block; however, a 13×13 board failed. This effect is exacerbated by the fact that the GPU also needs to maintain a massive word dictionary in its memory as well. Both these memory issues also introduce long data transfer times, which, as seen in our results, are by far the slowest part of the GPU approach. These slow data transfer times from memory outside the GPU are also the reason it would be inefficient to store the word paths in non-GPU memory.
In addition, during implementation I found that the problem may not have been as parallelizable as it first appeared. Firstly, I realized that each thread is performing different operations at any given time (as each thread searches for a different word across different tile paths), and thus we can expect severe thread divergence. Furthermore, the algorithm implementation is unintuitive due to the lack of available recursion on GPUs. You can see this by comparing the GPU and CPU algorithm code which, although implemented using similar search methodologies, are highly different due to non-recursion on the GPU. I also encountered difficulty in sharing classes between the CPU and GPU, as well as performing dynamic memory allocation within the kernel.
Looking To The Future
The limitations I just pointed out suggest avenues of future work, particularly in finding ways of reducing the memory footprint of the path traversal algorithm and the dictionary. One option which may reduce the dictionary size would be to use the prefix tree approach, which should in theory be more compact. However, this approach is also more naturally implemented when using recursion, so if possible you should use a recursion compatible GPU before attempting such an approach. Ideally, you’d want to find an alternate algorithm which does not require maintenance of the paths travelled within each thread, and instead simply shares the grid information across all threads; this would be the best way to reduce the memory issues.
Thanks for reading!
